What does Everything Is A File do?
Posted on
This post is in a series about "Everything Is A File":
- Is Everything A File?
- Measuring System Interface Complexity
- What does Everything Is A File do? (this post)
- The Filesystem Namespace
In particular, this post is looking at the "Everything is a file descriptor" meaning.
To see how the Everything Is A File approach works in practice, let's look at three kinds of classic resources that have been a part of Unix and the Everything Is A File tradition for a long time.
First, actual files.

Files are resizable arrays. They support random access to their data. Streaming access patterns are implemented on top of this, using a "current position" cursor.
Next, serial ports.
.jpg)
Serial ports can transmit and receive bytes. There are many protocols that can
be used with serial ports, but here, we're talking about Everything Is A File,
so we're going to look at what you get when you talk directly to a serial-port
device file, such as /dev/ttyS0 on a Unix system. This is a higher-level
interface than the hardware wires, but only by a little.
And third, TCP sockets.

TCP sockets are multiple abstraction layers removed from the hardware wires. They can also transmit and receive bytes, but they also have higher-level functionality, such as addressing that allows connections to be routed between many different wires.
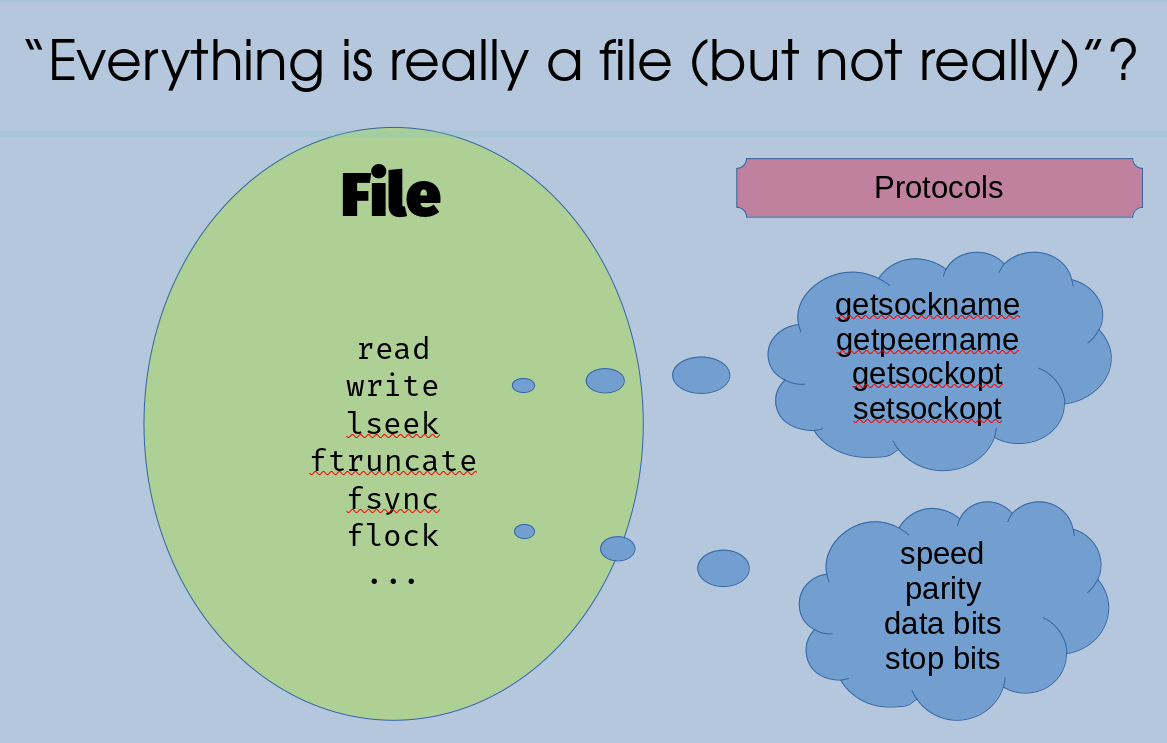
On their own, each of these three things has a set of functions that it naturally supports, like these:

These sets represent something inherent about each of these resources. Files have a "current position" cursor that can be moved with an "lseek" operation, but sockets and serial ports don't. TCP sockets have connections and one can query the IP address of the remote end, but files and serial ports don't. Files, serial ports, and TCP sockets are three different things, that support three different sets of operations.
But, the Everything Is A File approach says to treat them all as files. How does that work?
Read and Write
The first thing to notice here is that all three of these resources support
read and write. And, read and write are the only operations that show
up in all three of these resources.
One of the big reasons Everything Is A File works as well as it does is that
a lot of use cases only need read or write. As long as you
stick to one of those two operations, the Everything Is A File abstraction works
pretty well. Serial ports and TCP sockets can be thought of as infinite-length
files.
But, things get tricky. We said read or write above, but
what if you read and write? Serial ports and TCP sockets are both
interactive. It's common to write some bytes, and then read the response.
However, files aren't interactive. If you write some bytes and then do a read,
you'll read bytes from the array starting at the byte after the one you just
wrote to.

On serial ports and TCP sockets, interleaving reads and writes like this is very common. In files, it takes a lot of creativity to even imagine why one would ever want to do this.
Unix: Everything Is A File-SerialPort-TCPSocket-etc.
What happens if you try to call a file operation, like lseek, which seeks
the "current position" of a file to a different location, on a resource like
a serial port or a TCP socket, which doesn't have a concept of a "current position"?
// Open the serial device "file".
int fd = open("/dev/ttyUSB0", O_RDWR);
// Attempt to seek to byte-offset 8.
lseek(fd, SEEK_SET, 8) // Fails with `ESPIPE`, "Invalid seek".
Unix lets you to attempt this, and the operation fails at runtime. This is
effectively dynamic typing; the file descriptor refers to a resource with a
dynamic type, which in this case is "serial port". The lseek call does a
dynamic type check, and if dynamic type isn't "regular file", then the lseek
call fails.
So Everything Is A File doesn't mean that everything is really a file. There's still a distinct "serial port" type. Everything Is A File just means that you can use file APIs at compile time, and the types aren't checked until runtime.
And even though Unix invented the concept, Unix doesn't fully realize Everything Is A File. When Unix added sockets, it didn't insist on using only operations in the file API. Instead, it added a bunch of new functions. So in practice, it has one big combined API with all the functions that it supports available on all resources:

All these new functions fail at runtime if you pass them a file descriptor for something that isn't actually a socket.
Plan 9: Everything Is A ~~File~~Convention at Runtime
Unix didn't insist on rigidly following Everything Is A File when it came to sockets, but Plan 9 did. As we saw in Measuring System Interface Complexity, Plan 9's way of adding resource-specific functions while staying within the file API is to dynamically serialize requests as data, which can be written through the file API.
For example, for sockets, Plan 9 uses ASCII strings to encode commands like
"connect" and "accept" and send them to the network driver, which then parses
the ASCII strings and then calls the appropriate code inside the driver. This
way it can nominally use only the File API, since it's just using write, but
it can still make arbitrary function calls.
Unix's ioctl is another form of this pattern, where dynamic values determine
the callee. The same values can even have different meanings, depending on what
type of resource they're being used with.
Abstractions that don't abstract
Even though Everything Is A File is about using the file API in a very abstract
way, it doesn't end up providing much actual abstraction. It doesn't usually
let user code written to work with files automatically work with things that
aren't files, unless it's just using read or just using write.
Whether it's the Unix approach of having lots of functions that fail at runtime if the dynamic type is wrong, or the Plan 9 approach of serializing lots of functions into data that can be smuggled through the file API, user code still has to know what the dynamic type is in order to make meaningful use of it.
In all, Everything Is A File is often given credit for abstracting over widely
diverse resources. However it's really just read and write doing all the
abstracting. The rest of the file API doesn't enable reuse of logic across
different types.
So the real abstraction here is just Lots Of Things Are Streams.

The big picture
Other than the stream-style abstraction with read and write, a recurring theme in
Everything Is A File is deferring things which might otherwise be compile-time or link-time
concerns into runtime concerns. Type checks happen at runtime. And if we go all-in on
Everything Is A File, even function dispatch happens at runtime.
Doing all these things at runtime has many implications. One is that it opens up the possibility that core parts of program behavior could be influenced by malicious data. If function names are encoded as strings like "accept" or "connect", it's harder to ensure Control Flow Integrity (CFI) because it opens up opportunities for malicious code to cause other strings to be used instead, redirecting control flow to other functions.
Similarly, authorization becomes more complex because every single operation an application does is something which could dynamically represent something it shouldn't be permitted to do, so the platorm has to be continually performing authorization.
Another implication is that doing things at runtime makes it harder to understand programs without running them. If you want to know what resources a program will access, which functions it will use to do the access, the only way to be sure is to be there as it happens at runtime. This makes it harder to write interposition or virtualization layers, harder to know what resources an application will need ahead of time, and harder to figure out what's wrong when the application's assumptions of its environment aren't met.
So, if Everything Is A File has downsides, why do it?
There's more to say about the hierarchical namespace side of Everything Is A File in future posts, but here we're just looking at the file-descriptor meaning. And the main thing this meaning does is:
It works around the problem that adding new functions in Unix is hard.
Hard
Sometimes adding new functions in Unix is hard because you have to touch a lot of things. You probably need to touch multiple places in the kernel. You probably have touch touch the libc header files. You probably have to touch libc itself. And you probably have to teach source languages that have C FFI layers about the new function.
And sometimes these things are made harder by organizational reasons. When someone is writing a driver, and they often can't conveniently make changes to the core OS kernel or libc. Adding new functions in Unix and libc is often expected to be done with central coordination.
And sometimes adding new functions in Unix is hard because interfaces are described using C header files, and C header files don't contain enough information to auto-generate intermediaries, such as tracing tools, filtering tools, RPC protocols, bindings in languages other than C, and many other things. When you see a pointer, you don't know if it's a pointer to a single element or an array, and if it's an array, what the array length is. And either way you don't know if the memory is used for just the duration of the call, retained after the call, or freed by the call. C is accustomed to passing all of these concerns off to its users, but this means that it takes a lot of manual work when adding new functions to update everything.
And sometimes adding new functions in Unix is hard because new functions come with the expectation of long-term stability. The C ABI approach means that ABI details get baked into everything that interfaces with them. If you ever change the signature of a function, except in very specialized ways, you cause silent corruption for all users. And if you ever remove a function, you have to all the work you did to add the function in inverse. So in practice, you don't add new functions, unless you're really ready to commit to them for the long term.

So the big advantage of this meaning of Everything Is A File is that you can add new logical functions while avoiding the difficulties of adding new actual functions.
The 9p protocol
Plan 9 has an additional consideration: It has a protocol, called 9p, which encodes a kind of file API. This ends up being another arena where adding new functions is hard.
A network protocol needs a specification, and 9p has one, but it's kind of an anti-specification. It defines just enough functionality to work with a hierarchical namespace and files, and excludes everything else. It deliberately doesn't define the rest of the protocol, pushing everything else out to dynamic conventions, like String OS. This is very convenient for a spec, because specs take a lot of work to maintain.
In a spec, adding new functions is hard.
What if...
The constraints that make adding new functions in Unix and other domains hard have been with us for a long time, such that we don't always realize when it's there, shaping the way the systems around us work, and even shaping the way we think about new systems.
Everything Is A File bundles up a wide range of assumptions in a way that aren't always easy to see. If we unpack those assumptions, it helps us ask the question:
What if we designed systems differently?